08. Introduction to LSTMs
Recurrent Neural Networks (RNNs)
In the Deep Learning section, in Term-1, we covered different types of deep neural networks. In all those architectures, the networks were trained using the current input only. These architectures, specifically feed-forward networks, had the limitation that they did not have a memory element to them. RNNs are a type of neural network which utilize memory, i.e. the previous state, to predict the current output.
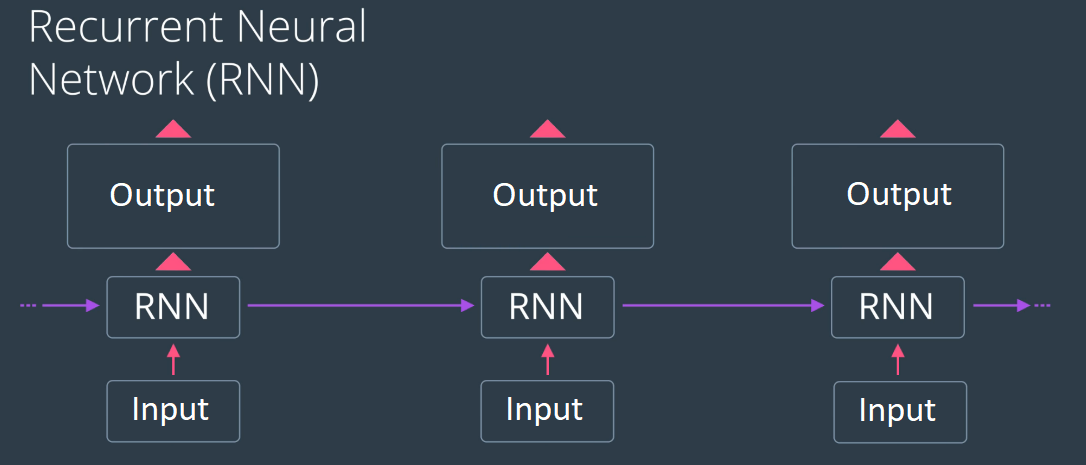
RNNs have a wide range of applications, such as in natural language processing for machine translation, in computer vision for gesture recognition, speech recognition etc. But they also have certain limitations. RNNs are more effective when they are only trying to learn from the most recent information. For example, if we were trying to predict the last word in the sentence -
my mobile robot has four …,
an RNN would be able to predict the last word as wheels with high probability given the context. However, if the sentence was far longer and complicated, the RNN would struggle to maintain the context over each timestep and predict the last word with high probability.
This shortcoming of RNNs, where they are unable to learn from long-term dependencies, is handled by another architecture called Long Short Term Memory, or LSTM.
LSTMs
The LSTM architecture keeps track of both, the long-term memory and the short-term memory, where the short-term memory is the output or the prediction. The architecture of LSTM consists of four “gates” that carry out specific functions -
- Forget Gate - The long-term memory is input to this gate and any information that is not useful, is removed.
- Learn Gate - The short-term memory is input to this gate, along with the input (or event) to the LSTM at current timestep. It contains or outputs information that is recently learned and removes any non-useful information.
- Remember Gate - The output of the Forget Gate and the Learn Gate are fed into the Remember Gate, and it outputs an updated long-term memory.
- Use Gate - This gate uses the information from the Learn gate and the Forget Gate to make a prediction. This prediction acts as the short-term memory for the next timestep.
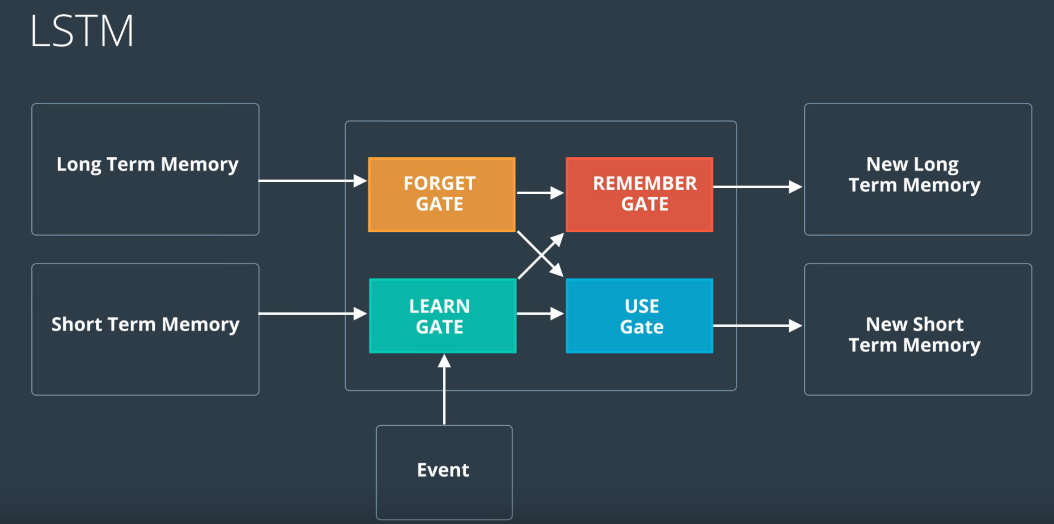
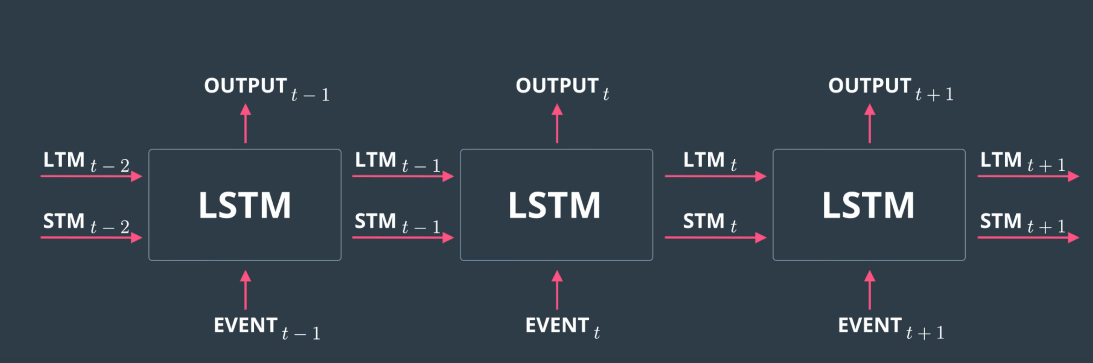
The image above represents a single LSTM unit or cell. The following image is an example of a network which depicts multiple LSTM nodes:
Project Hyperparameters
For the project, every camera frame, at every simulation iteration, is fed into the DQN and the agent then makes a prediction and carries out an appropriate action. Using LSTMs as part of that network, you can train your network by taking into consideration multiple past frames from the camera sensor instead of a single frame.
The network in [DQN.py](link to file) has been defined such that you can include LSTMs into the network easily. In ArmPlugin.cpp, two variables have been defined that can be used to incorporate LSTMs in the DQN:
USE_LSTM- This variable can be set to eithertrueorfalse.LSTM_SIZE- Size of each LSTM cell.
The above variables can be treated as hyperparameters when training the RL agent for the project.
Additional Resources
Here is a list of some resources to understand RNNs and LSTMs in more detail:
- Andrej Karpathy's lecture on RNNs and LSTMs from CS231n
- Chris Olah's LSTM post
- Friendly Introduction to RNNs by Luis Serrano
- RNN and LSTM by Brandon Rohrer